In everyday life, we have a good sense of the quantity of various items in terms of a "single" number. For example, we know what it means to buy 5 pounds of flour and it is more than 3 pounds of flour. But, we don't have a very intuitive sense of quantity and comparison in case of some mathematical objects such as vector and matrix.

For example, how big is a vector like the one below?
$[ 98, 1, 23, 6 ]$
Is it bigger than the following vector?
$[ 2, 97, 12, 13 ]$

What about the two matrices below?

It is not very intuitive to compare vectors and matrices, because a matrix is a collection of numbers, not just a single number. We need to define a way to interpret the size (or the quantity) of a collection of numbers, whether it is a vector or it is a matrix.
Norms
The size of a matrix or a vector is defined based on a "norm". You can say that the higher is the norm of matrix, the bigger is the size of the matrix (of course, it is not a precise definition, but you get the idea). Unlike the value of a single number, there is no unique way to interpret the size of a vector or a matrix. There are many different types of norms and each one has its own properties and uses.

Some of the famous norms include the Euclidean norm, l0 norm, l1 norm, Frobenius norm, etc. The following table shows the famous vector norms.

There are also a number of matrix norms. The matrix norms $l_0$ through $l_\infty$ can be defined in a number of different ways, for example by adding up all the entries, or as a result of multiplying by a vector.

We will explain a couple of vector norms and matrix norms later. But first let's use a more precise mathematical notation of norm. The norm of a matrix $X$ is denoted by $||X||_i$ where $i$ denotes the type of the norm, e.g. if it is norm 0, we will denote it as $||X||_0$, and if it is the Euclidean norm, we will show it as $||X||_2$. Note that Euclidean norm is more commonly denoted as $||X||$, as it is the one of the most widely used norms, therefore the subscript is usually omitted.

Some of the famous norms include the Euclidean norm, l0 norm, l1 norm, Frobenius norm, etc. The following table shows the famous vector norms.

There are also a number of matrix norms. The matrix norms $l_0$ through $l_\infty$ can be defined in a number of different ways, for example by adding up all the entries, or as a result of multiplying by a vector.

We will explain a couple of vector norms and matrix norms later. But first let's use a more precise mathematical notation of norm. The norm of a matrix $X$ is denoted by $||X||_i$ where $i$ denotes the type of the norm, e.g. if it is norm 0, we will denote it as $||X||_0$, and if it is the Euclidean norm, we will show it as $||X||_2$. Note that Euclidean norm is more commonly denoted as $||X||$, as it is the one of the most widely used norms, therefore the subscript is usually omitted.
Vector Norms
First, we define the vector norms and then we will explain the matrix norms.Euclidean Norm
The Euclidean norm (i.e. $l_2$ norm) of a vector X is defined as:
$||X|| = \sqrt{\sum_i{x_i^2}}$
$l_2$ norm is used in many applications, because it is continuous and differentiable.
$l_2$ norm has a very simple geometric interpretation, shown in the following figure. Here, $l_2$ norm shows the distance of a 2D point (i.e. a vector with only two elements) from the origin (it is the shortest path).

$l_2$ norm has a very simple geometric interpretation, shown in the following figure. Here, $l_2$ norm shows the distance of a 2D point (i.e. a vector with only two elements) from the origin (it is the shortest path).

Another useful illustration of the Euclidean norm is its unit circle, i.e. all the set of all vectors whose Euclidean norm is equal to "1". You will realize that the set of all such vectors lie on a circle with a radius 1.

$l_n$ norms in General
In general, $l_n$ norm can be defined as:
$||X||_n = \sqrt[n]{\sum_i{x_i^n}}$
These norms might look similar, but they have very different properties, therefore those norms are not interchangeable in most cases.
$l_0$ Norm
If you look carefully at the above formula, then you will realize that there is a problem ... we mentioned $l_0$ norm. But how do we define $l_0$ norm with the presence of $\sqrt[0]{..}$ and $x_i^0$?! Well, as computing the above norm formula for $l_0$ is quite tricky, in practice we use the following definition of $l_0$:
$||X||_0 = \# (i | x_i \neq 0)$
The above definition tells us that $l_0$ norm of a vector $X$ is the total number of its non-zero elements. You might think that the above norm is just a mathematical definition with perhaps no real world application. In reality $l_0$ norm shows up in many optimization problems, however as its computation is difficult, we usually use other norms such as $l_1$.
$l_1$ Norm
$l_1$ norm is defined as:$||X||_1 = \sum_i{|x_i|}$
$l_0$ norm is used in many applications, and it has a couple of other names such as the "Manhattan distance". It is used in many regularization and optimization problems instead of $l_0$ which is more difficult to compute (see this post). $l_1$ also has a simple geometric interpretation, as shown in the following figure. It shows the distance in terms of "city blocks", hence sometimes it is called "Manhattan distance" or "city block distance".
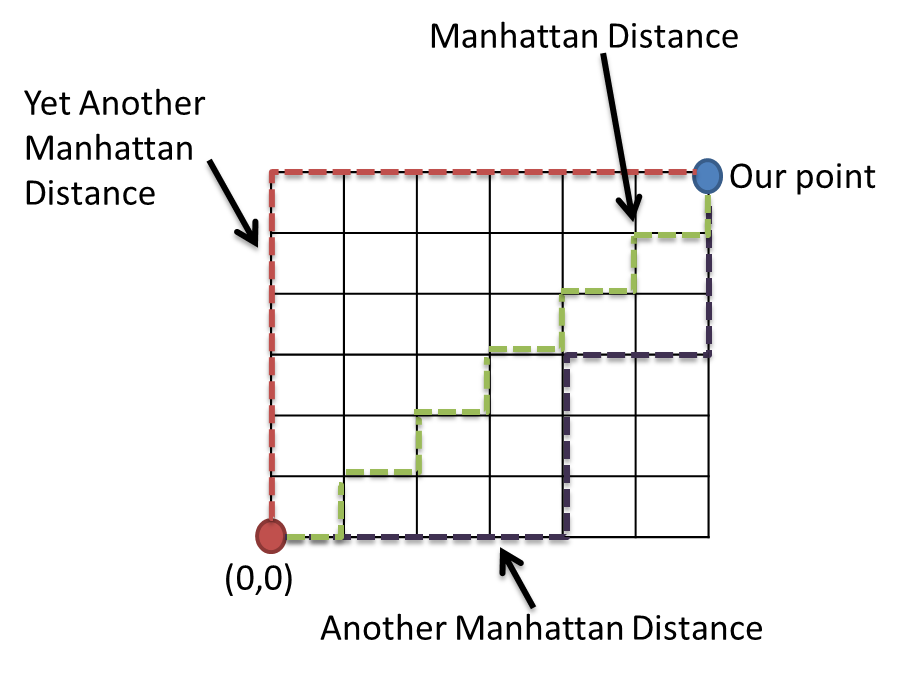
Similar to Euclidean norm, we can also show its unit circle, i.e. all the set of all vectors whose $l_1$ norm is equal to "1". You will realize that the set of all such vectors lie on a square (and not a circle) with its sides equal to 1.

$l_\infty$ Norm
$l_\infty$ Norm is defined as:
$||X||_\infty = \max{(|x_1|, \cdots, |x_n|)}$
It is sometimes called as the Chebyshev norm. The geometric interpretation of its unit circle is a square with sides of 1. It has this particular shape, because in order to have a norm of 1, at least one of the entries has to be 1.

What about a matrix?
A matrix norm is a natural extension of a vector norm. There are number of different matrix norms. Here, we explain a couple of these norms: induced norms (defined for $l_0$ through $l_\infty$), entry-wise norms (defined for $l_0$ through $l_\infty$), and Schatten norms (defined for $l_0$ through $l_\infty$).
$|A||_p=\max_{x \neq 0}{\frac{||Ax||_p}{||x||_p}}$
(We call it "induced" norm because we use $x$ to induce the norm.)
$||A||_1 = \max_j{\sum_i{|a_{ij}|}}$
which means that we will add all the entries in each column and then will pick the maximum value. For example, if we have the following matrix (it is the same matrix shown on the scale at the beginning of this post)
$
A =
\begin{pmatrix}
8 & 12 & 1 \\
3 & 4 & 6 \\
56 & 16 & 76 \\
\end{pmatrix}
$
Its norm $||A_1||$ will be $\max{\{8+3+56, 12+4+16, 1+6+76\}}$ or $\max{\{67, 32, 83\}} = 83$
Another example:
$
B =
\begin{pmatrix}
9 & 11 & 4 \\
3 & 4 & 7 \\
50 & 10 & 63 \\
\end{pmatrix}
$
Its norm $||B_1||$ will be $\max{\{9+3+50,11+4+10, 7+7+63\}}$ or $\max{\{62,25,77\}} = 77$.

$||A||_2 = \sqrt{\lambda_{max}(A^*A)}$
Where $A^*$ is the conjugate transpose of $A$. In other words, $||A||_2$ is the square root of the largest eigenvalue of $A^*A$. Note that if all the entries of your matrix are real (i.e. the entries have no imaginary part), then the conjugate transpose is simply the transpose matrix.
For $p=2$, we will have "Frobenius norm" or the "Hilbert–Schmidt norm".
$||A||_2 = \sqrt{\sum_i{\sum_j{|a_{ij}|^2}}}$
It is interesting to note that the Frobenius norm can be computed from "trace" (i.e. the sum of singular values) of matrix $A^*A$
$||A||_2 = \sqrt{trace (A^*A)} =\sqrt{\sum_i{\sigma_i^2}}$
Here $\sigma_i$ denotes the $i$-th singular value.
$||A||_p = \sqrt[p]{\sum_i{\sigma_i^p}}$
In case of $p=1$, this is called "nuclear norm".
$||A||_1 = trace\{A^*A\} =\sum_i{\sigma_i}$
Induced Matrix Norm
The "induced" matrix norm $l_p$ (p-norm) is defined as:$|A||_p=\max_{x \neq 0}{\frac{||Ax||_p}{||x||_p}}$
(We call it "induced" norm because we use $x$ to induce the norm.)
Induced Matrix Norm $||A||_1$
In case of $p=1$, this can be written as:$||A||_1 = \max_j{\sum_i{|a_{ij}|}}$
which means that we will add all the entries in each column and then will pick the maximum value. For example, if we have the following matrix (it is the same matrix shown on the scale at the beginning of this post)
$
A =
\begin{pmatrix}
8 & 12 & 1 \\
3 & 4 & 6 \\
56 & 16 & 76 \\
\end{pmatrix}
$
Its norm $||A_1||$ will be $\max{\{8+3+56, 12+4+16, 1+6+76\}}$ or $\max{\{67, 32, 83\}} = 83$
Another example:
$
B =
\begin{pmatrix}
9 & 11 & 4 \\
3 & 4 & 7 \\
50 & 10 & 63 \\
\end{pmatrix}
$
Its norm $||B_1||$ will be $\max{\{9+3+50,11+4+10, 7+7+63\}}$ or $\max{\{62,25,77\}} = 77$.
Induced Matrix Norm $||A||_2$: Known as Spectral Norm
In case of $p=2$, the matrix norm is called spectral norm and it is defined as:$||A||_2 = \sqrt{\lambda_{max}(A^*A)}$
Where $A^*$ is the conjugate transpose of $A$. In other words, $||A||_2$ is the square root of the largest eigenvalue of $A^*A$. Note that if all the entries of your matrix are real (i.e. the entries have no imaginary part), then the conjugate transpose is simply the transpose matrix.
Entry-wise Matrix Norm
It is also possible to define entry-wise norm of a matrix. This is very similar to how we defined norms for a vector:
$||A||_p = \sqrt[p]{\sum_i{\sum_j{|a_{ij}|^p}}}$
For $p=2$, we will have "Frobenius norm" or the "Hilbert–Schmidt norm".
$||A||_2 = \sqrt{\sum_i{\sum_j{|a_{ij}|^2}}}$
It is interesting to note that the Frobenius norm can be computed from "trace" (i.e. the sum of singular values) of matrix $A^*A$
$||A||_2 = \sqrt{trace (A^*A)} =\sqrt{\sum_i{\sigma_i^2}}$
Here $\sigma_i$ denotes the $i$-th singular value.
Schatten Norms
The Schatten norms apply the p-norm to singular values of a matrix:$||A||_p = \sqrt[p]{\sum_i{\sigma_i^p}}$
In case of $p=1$, this is called "nuclear norm".
$||A||_1 = trace\{A^*A\} =\sum_i{\sigma_i}$
No comments:
Post a Comment